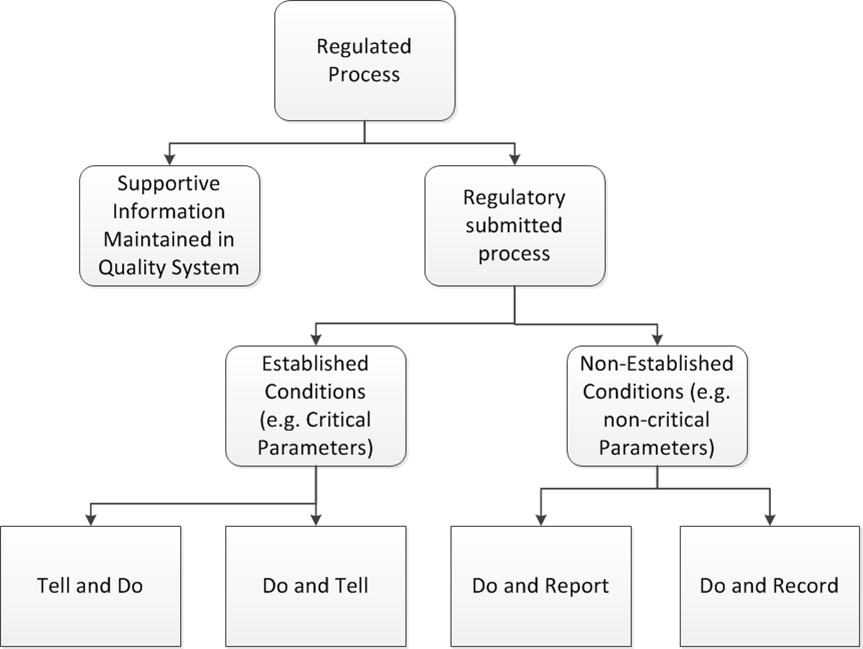
The FDA has announced a pilot program to “propose explicit established conditions (ECs) as part of an original new drug application (NDA), abbreviated new drug application (ANDA), biologics license application (BLA), or as a prior approval supplement (PAS) to any of these.”
With data integrity on everyone’s mind the last few years, the role of a data steward is being more and more discussed. Putting aside my amusement on the proliferation of stewards and champions across our quality systems, the idea of data stewards is a good one.
Data steward is someone from the business who handle master data. It is not an IT role, as a good data steward will truly be invested in how the data is being used, managed and groomed. The data steward is responsible and accountable for how data enters the system and ensure it adds value to the process.
The job revolves around, but is not limited to, the following questions:
Why is this particular data important to the organization?
How long should the particular records (data) be stored or kept?
Measurements to improve the quality of that analysis
Data stewards do this by providing:
Operational Oversight by overseeing the life cycle through defining and implementing policies and procedures for the day-to-day operational and administrative management of systems and data — including the intake, storage, processing, and transmission of data to internal and external systems. They are accountable to define and document data and terminology in a relevant glossary. This includes ensuring that each critical data element has a clear definition and is still in use.
Data quality, including evaluation and root cause analysis
Risk management, including retention, archival, and disposal requirements and ensuring compliance with internal policy and regulations.
With systems being made up of people, process and technology, the line between data steward and system owner is pretty vague. When a technology is linked to a single system or process it makes sense for them to be the same person (or team), for example a document management system. However, most technology platforms are across multiple systems or processes (for example an ERP or Quality Management System) and it is critical to look at the technology holistically as the data steward. I think we are all familiar with the problems that can be created by the same piece of data being treated differently between workflows in a technology platform.
As organizations evolve their data governance I think we will see the role of the data steward become more and more part of the standard quality toolbox, as the competencies are pretty similar.
Our research suggests that the bystander effect can be real and strong in organizations, especially when problems linger out in the open to everyone’s knowledge.
The bystander effect occurs when the presence of others discourages an individual from intervening in an emergency situation. When individuals relinquish responsibility for addressing a problem, the potential negative outcomes are wide-ranging. While a great deal of the research focuses on helping victims, the overcoming the bystander effect is very relevant to building a quality culture.
The literature on this often follows after social psychologists John M. Darley and Bibb Latané who identified the concept in the late ’60s. They defined five characteristics bystanders go through:
Notice that something is going on
Interpret the situation as being an emergency
Degree of responsibility felt
Form of assistance
Implement the action choice
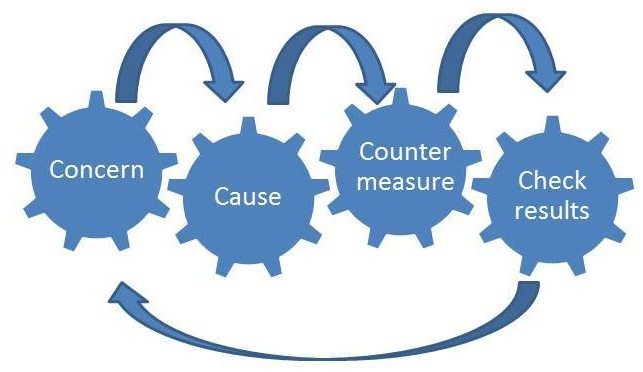
This is very similar to the 5 Cs of trouble-shooting: Concern (Notice), Cause (Interpret), Countermeasure (Form of Assistance and Implement), Check results.
What is critical here is that degree of responsibility felt. Without it we see people looking at a problem and shrugging, and then the problem goes on and on. It is also possible for people to just be so busy that the degree of responsibility is felt to the wrong aspect, such as “get the task done” or “do not slow down operations” and it leads to the wrong form of assistance – the wrong troubleshooting.
When building a quality culture, and making sure troubleshooting is an ingrained activity, it is important to work with employees so they understand that their voices are not redundant and that they need to share their opinions even if others have the same information. As the HBR article says: “If you see something, say something (even if others see the same thing).”
Building a quality culture is all about building norms which encourage detection of potential threats or problems and norms which encouraged improvements and innovation.
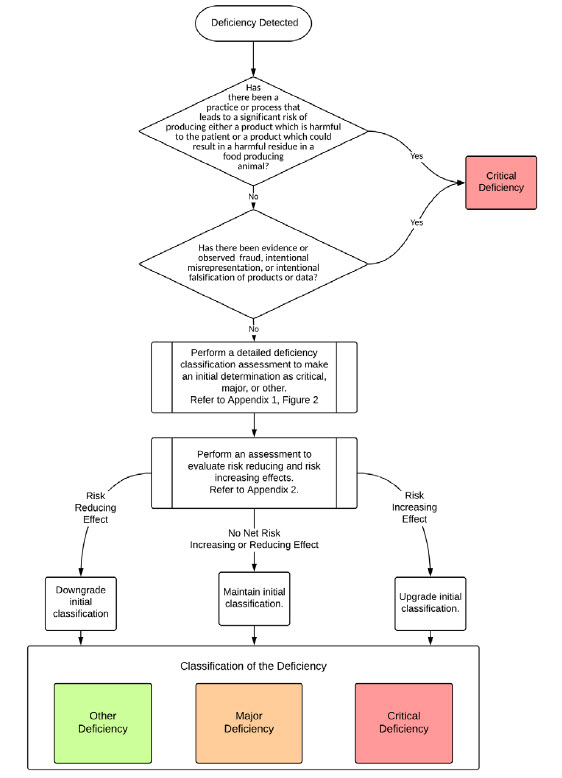
The Pharmaceutical Inspection Convention Cooperation Scheme (PIC/S) on 01-Jan-2019 released a long-awaited guidance to help regulators harmonize the classification and reporting of good manufacturing practice (GMP) deficiency outcomes from inspections. The guidance is designed as a “tool to support the risk-based classification of GMP deficiencies from inspections and to establish consistency amongst inspectorates.”
I recently had a discussion with one of the best root cause investigators and problem solvers I know, Thor McRockhammer. Thor had concerns about a case where the expected conditions were not met and there were indications that individuals engaged in troubleshooting and as a result not only made the problem worse but led to a set of issues that seem rather systematic.
Our conversation (which I do not want to go into too much detail on) was a great example of troubleshooting going wrong.
Troubleshooting is defined as “Reactive problem solving based upon quick responses to immediate symptoms. Provides relief and immediate problem mitigation. But may fail to get at the real cause, which can lead to prolonged cycles of firefighting.” Troubleshooting usually goes wrong one of a few ways:
Not knowing when troubleshooting shouldn’t be executed
Using troubleshooting exclusively
Not knowing when to go to other problem solving tools (usually “Gap from standard”) or to trigger other quality systems, such as change management.
Troubleshooting is a reactive process of fixing problems by rapid response and short-term corrective actions. It covers noticing the problem, stopping the damage and preventing spread of the problem.
So if our departure from expected conditions was a leaky gasket, then troubleshooting is to try to stop the leak. If our departure is a missing cart then troubleshooting usually involves finding the cart.
Troubleshooting puts things back into the expected condition without changing anything. It addresses the symptom and not the fundamental problems and their underlying causes. They are carried out directly by the people who experience the symptoms, relying upon thorough training, expertise and procedures designed explicitly for troubleshooting.
With out leaky gasket example, our operators are trained and have procedural guidance to tighten or even replace a gasket. They also know what not to do (for example don’t weld the pipe, don’t use a different gasket, etc). There is also a process for documenting the troubleshooting happened (work order, comment, etc).
To avoid the problems listed above troubleshooting needs a process that people can be thoroughly trained in. This process needs to cover what to do, how to communicate it, and where the boundaries are.
·What do we known about the exact nature of the problem?
·What do your
standards say about how this concern should be documented?
oFor example,
can be addressed as a comment or does it require a deviation or similar non-conformance
·If the concern stems
from a requirement it must be documented.
Cause
·What do you
know about the apparent (or root) cause of the problem?
·Troubleshooting
is really good at dealing with superficial cause-and-effect relationships. As
the cause deepens, fixing it requires deeper problem-solving.
·The cause can
be a deficiency or departure from a standard
Countermeasure
·What immediate
or temporary countermeasures can be taken to reduce or eliminate the problem?
·Are follow-up
or more permanent countermeasures required to prevent recurrence?
oIf so, do you
need to investigate more deeply?
·Countermeasures
need to be evaluated against change management
·Countermeasures
cannot ignore, replace or go around standards
·Apply good
knowledge management
Check results
·Did the results
of the action have any immediate effect on eliminating the concern or
problem?
·Does the
problem repeat?
oIf so, do you
need to investigate more deeply?
·Recurrence
should trigger deeper problem-solving and be recorded in the quality system.
·Beware troubleshooting
countermeasures becoming tribal knowledge and the new way of working
Trouble shooting is in a box
Think of your standards as a box. This box defines what should happen per our qualified/validated state, our procedures, and the like. We can troubleshoot as much as we want within the box. We cannot change the box in any way, nor can we leave the box without triggering our deviation/nonconformance system (reactive) or entering change management (proactive).
Communication is critical for troubleshooting
Troubleshooting processes need a mechanism for letting supervisors happen. Troubleshooting that happens in the dark is going to cause a disaster.
Operators need to be trained how to document troubleshooting. Sometimes this is as simple as a notation or comment, other-times you trigger a corrective action process.
Engaging in troubleshooting, and not documenting it starts to look a like fraud and is a data integrity concern.
Change Management
The change management process should be triggered as a result of troubleshooting. Operators should be trained to interpret it. This is often were concept of exact replacements and like-for-like come in.
It is trouble shooting to replace a part with an exact part. Anything else (including functional equivalency) is a higher order change management activity. It is important that everyone involved knows the difference.
Covers
Is it troubleshooting?
Like-for- Like
Spare parts that are identical replacements (has the same the same manufacturer, part number, material of construction, version)
Existing contingency procedures (documented, verified, ideally part of qualification/validation)
Yes
This should be built into procedures like corrective maintenance, spare parts, operations and even contingency procedures.
Functionally equivalent
Equivalent, for example, performance, specifications, physical characteristics, usability, maintainability, cleanability, safety
No
Need to understand root cause. Need to undergo appropriate level of change management
New
Anything else
No
Need to understand root cause. Need to undergo appropriate level of change management
This applies to both administrative and technical controls.
ITIL Incident Management
ITIL Incident Management (or similar models) is just troubleshooting and has all the same hallmarks and concerns.
Conclusion
Trouble shooting is an integral process. And like all processes it should have a standard, be trained on, and go through continuous improvement.