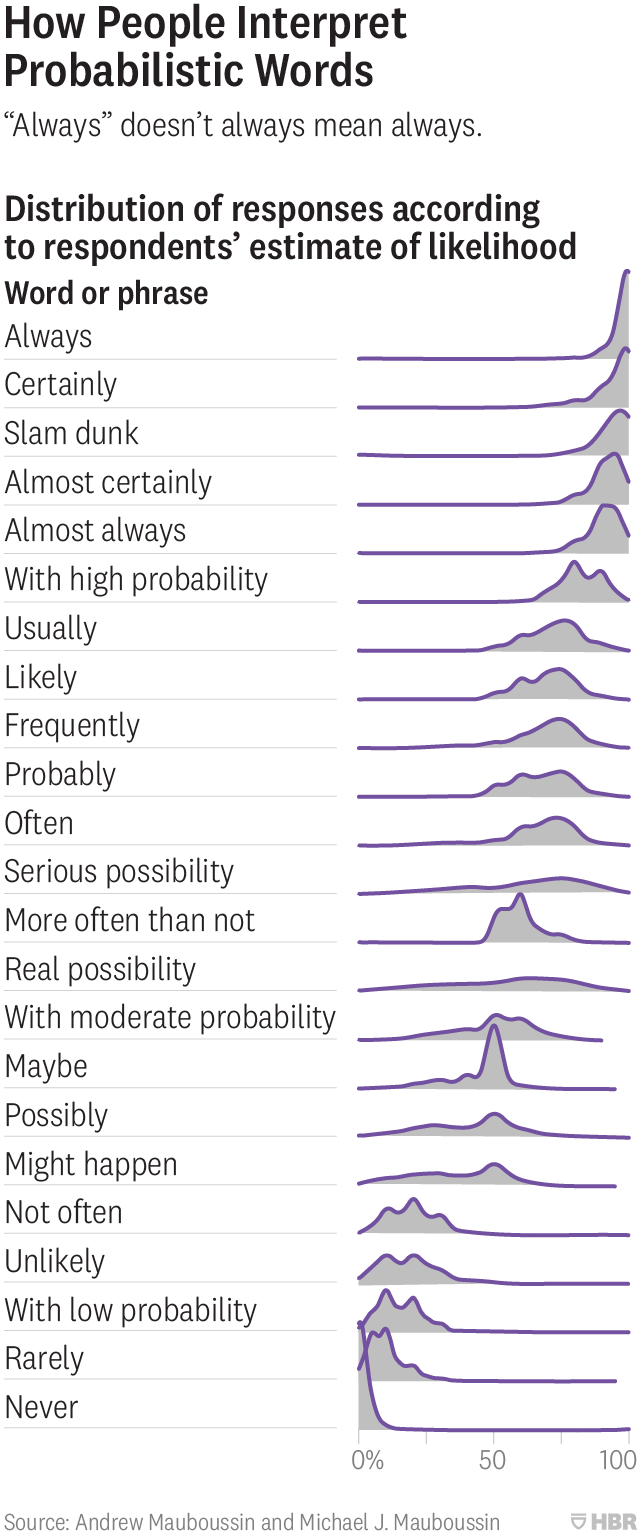
The July-2019 monthly gift to members of the ASQ is a lot of material on Failure Mode and Effect Analysis (FMEA). Reading through the material got me to thinking of subjectivity in risk management.
Risk assessments have a core of the subjective to them, frequently including assumptions about the nature of the hazard, possible exposure pathways, and judgments for the likelihood that alternative risk scenarios might occur. Gaps in the data and information about hazards, uncertainty about the most likely projection of risk, and incomplete understanding of possible scenarios contribute to uncertainties in risk assessment and risk management. You can go even further and say that risk is socially constructed, and that risk is at once both objectively verifiable and what we perceive or feel it to be. Then again, the same can be said of most of science.
Risk is a future chance of loss given exposure to a hazard. Risk estimates, or qualitative ratings of risk, are necessarily projections of future consequences. Thus, the true probability of the risk event and its consequences cannot be known in advance. This creates a need for subjective judgments to fill-in information about an uncertain future. In this way risk management is rightly seen as a form of decision analysis, a form of making decisions against uncertainty.
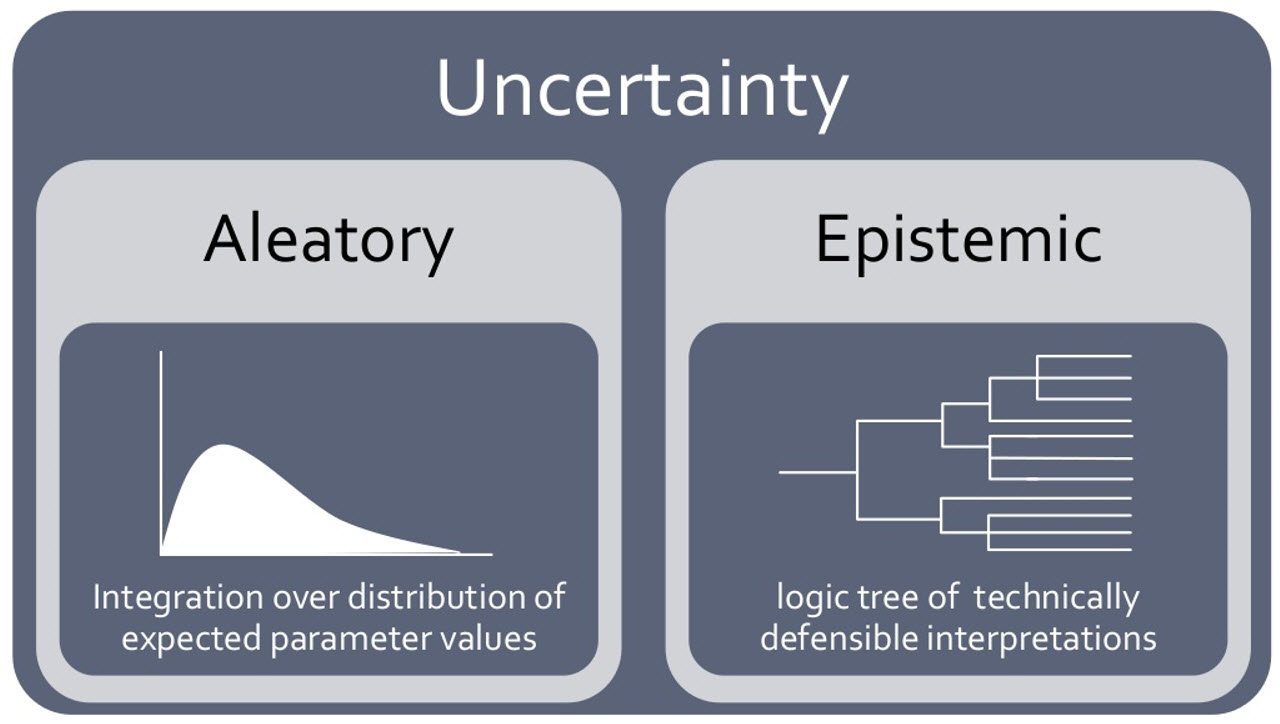
Everyone has a mental picture of risk, but the formal mathematics of risk analysis are inaccessible to most, relying on probability theory with two major schools of thought: the frequency school and the subjective probability school. The frequency school says probability is based on a count of the number of successes divided by total number of trials. Uncertainty that is ready characterized using frequentist probability methods is “aleatory” – due to randomness (or random sampling in practice). Frequentist methods give an estimate of “measured” uncertainty; however, it is arguably trapped in the past because it does not lend itself to easily to predicting future successes.
In risk management we tend to measure uncertainty with a combination of frequentist and subjectivist probability distributions. For example, a manufacturing process risk assessment might begin with classical statistical control data and analyses. But projecting the risks from a process change might call for expert judgments of e.g. possible failure modes and the probability that failures might occur during a defined period. The risk assessor(s) bring prior expert knowledge and, if we are lucky, some prior data, and start to focus the target of the risk decision using subjective judgments of probabilities.
Some have argued that a failure to formally control subjectivity — in relation to probability judgments – is the failure of risk management. This was an argument that some made during WCQI, for example. Subjectivity cannot be eliminated nor is it an inherent limitation. Rather, the “problem with subjectivity” more precisely concerns two elements:
- A failure to recognize where and when subjectivity enters and might create problems in risk assessment and risk-based decision making; and
- A failure to implement controls on subjectivity where it is known to occur.
Risk is about the chance of adverse outcomes of events that are yet to occur, subjective judgments of one form or another will always be required in both risk assessment and risk management decision-making.
We control subjectivity in risk management by:
- Raising awareness of where/when subjective judgments of probability occur in risk assessment and risk management
- Identifying heuristics and biases where they occur
- Improving the understanding of probability among the team and individual experts
- Calibrating experts individually
- Applying knowledge from formal expert elicitation
- Use expert group facilitation when group probability judgments are sought
Each one of these is it’s own, future, post.