I’m on the record in believing that Quality as a process is an inherently progressive one and that when we stray from those progressive roots we become exactly what we strive to avoid. One only has to look at the history of Six Sigma, TQM, and even Lean to see that.
I’m a big proponent of Humanocracy for that very reason.
One cannot read much of business writing without coming across the great leader (or even worse great man) hypothesis, which serves to naturalize power and existing forms of authority. One cannot even escape the continued hagiography of Jack Welch, even though he’s been discredited in many ways for his toxic legacy.
We cannot drive out fear unless we unmask power by revealing its contradictions, hypocrisies, and reliance on violence and coercion. The way we work is a result of human decisions, and thus capable of being remade.
We all have a long way to go here. I, for example, catch myself all the time speaking of leadership in hierarchical ways. One of the current things I am working on is exorcising the term ‘leadership team’ from my vocabulary. It doesn’t serve any real purpose and it fundamentally puts the idea of leadership as a hierarchical entity.
Another thing I am working on is to tackle the thorn of positional authority, the idea that the higher the rank in the organization the more decision-making authority you have. Which is absurd. In every organization, I’ve been in people have positions of authority that cover areas they do not have the education, experience, and training to make decisions in. This is why we need to have clear decision matrixes, establish empowered process owners and drive democratic leadership throughout the organization.
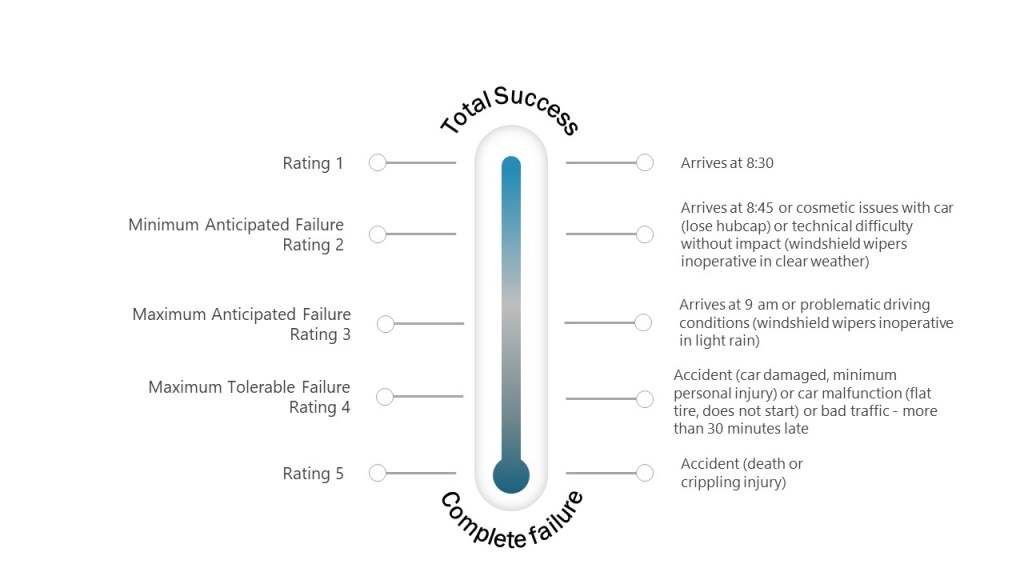
When evaluating a system we can look at it in two ways. We can identify ways a thing can fail or the various ways it can succeed.
Success/Failure Space
These are really just two sides of the coin in many ways, with identifiable points in success space coinciding with analogous points in failure space. “Maximum anticipated success” in success space coincides with “minimum anticipated failure” in failure space.
Like everything, how we frame the question helps us find answers. Certain questions require us to think in terms of failure space, others in success. There are advantages in both, but in risk management, the failure space is incredibly valuable.
It is generally easier to attain concurrence on what constitutes failure than it is to agree on what constitutes success. We may desire a house that has great windows, high ceilings, a nice yard. However, the one we buy can have a termite-infested foundation, bad electrical work, and a roof full of leaks. Whether the house is great is a matter of opinion, but we certainly know all it is a failure based on the high repair bills we are going to accrue.
Success tends to be associated with the efficiency of a system, the amount of output, the degree of usefulness. These characteristics are describable by continuous variables which are not easily modeled in terms of simple discrete events, such as “water is not hot” which characterizes the failure space. Failure, in particular, complete failure, is generally easy to define, whereas the event, success, maybe more difficult to tie down
Theoretically the number of ways in which a system can fail and the number of ways in which a system can ·succeed are both infinite, from a practical standpoint there are generally more ways to success than there are to failure. From a practical point of view, the size of the population in the failure space is less than the size of the population in the success space. This leads to risk management focusing on the failure space.
The failure space maps really well to nominal scales for severity, which can be helpful as you build your own scales for risk assessments.
For example, let’s look at an example of a morning commute.
Example of the failure space for a morning commute
The pictorial tree is a favorite for representing branching paths. Some common ones include Fault Tree Analysis (FTA); Cause Trees to analyze used retrospectively to analyze events that have already occurred; Question Trees to aid in problem-solving; and, even Success Trees to figure out why something went right.
Apple Tree illustration with long branching roots
Inductive or Deductive
Inductive Reasoning: Induction is reasoning from individual cases to a general conclusion. We start from a particular initiating condition and attempt to ascertain the effect of that fault or condition on a system. Deductive Reasoning: Deduction is reasoning from the general to the specific. We start with the way the system has failed and we attempt to find out what modes of system behavior contribute to this failure.
The beauty of a pictorial representation is that depending on which way you go on the tree pictorially represents the form of reasoning that is used.
Inductive reasoning is the branches, and tools like a Cause Tree, are used to determine what system states (usually failed states) are possible. The inductive techniques provide answers to the generic question, “What happens if–?” The process consists of assuming a particular state of existence of a component or components and analyzing to determine the effect of that condition on the system.
Deductive reasoning is the roots, and tools like Fault Tree Analysis, take some specific system state, which is generally a failure state, and chains of more basic faults contributing to this undesired events are built up in a systematic way to determine how a given failure can occur.
Success/Failure Space
We operate in a success/failure space. We are constantly identifying ways a thing can fail or the various ways of success.
Success/Failure Space
These are really just two sides of the coin in many ways, with identifiable points in success space coinciding with analogous points in failure space. “Maximum anticipated success” in success space coincides with “minimum anticipated failure” in failure space.
Like everything, how we frame the question helps us find answers. Certain questions require us to think in terms of failure space, others in success. There are advantages in both, but in risk management, the failure space is incredibly valuable.
Fault Tree Analysis
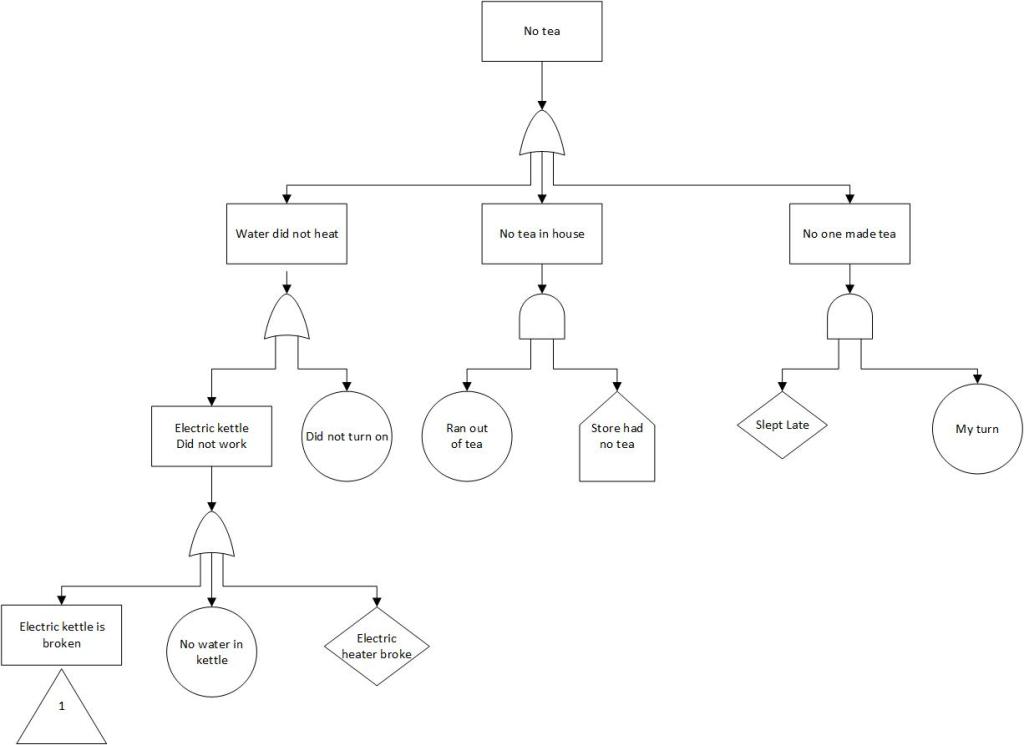
Fault Tree Analysis (FTA) is a tool for identifying and analyzing factors that contribute to an undesired event (called the “top event”). The top event is analyzed by first identifying its immediate and necessary causes. The logical relationship between these causes is represented by several gates such as AND and OR gates. Each cause is then analyzed step-wise in the same way until further analysis becomes unproductive. The result is a graphical representation of a Boolean equation in a tree diagram.
The Undesired Event
Fault tree analysis is a deductive failure analysis that focuses on one particular undesired event to determine the causes of this event. The undesired event constitutes the top event in a fault tree diagram and generally consists of a complete failure.
If the top event is too general, the analysis becomes unmanageable; if it is too specific, the analysis does not provide a sufficiently broad view.
Top events are usually a failure of a critical requirement or process step.
A fault tree is not a model of all possible failures or all possible causes for failure. A fault tree is tailored to its top event which corresponds to some particular failure mode, and the fault tree includes only those faults that contribute to this top event. These faults are not exhaustive – they cover only the most credible faults as assessed by the risk team.
The Symbology of a Fault Tree
Events
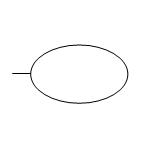
Base Event
The circle describes a basic initiating fault event that requires no further development. The circle signifies that the appropriate limit of resolution has been reached.
Undeveloped Event
The diamond describes a specific fault event that is not further developed, either because the event is of insufficient consequence or because information relevant to the event is unavailable.
Conditioning Event
The ellipse is used to record any conditions or restrictions that apply to any logic gate. It is used primarily with the INHIBIT and PRIORITY AND-gates.
External Event
The house is used to signify an event that is normally expected to occur: e.g., a phase change. The house symbol displays events that are not, of themselves, faults.
External does not mean external to the organization.
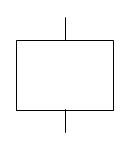
Intermediate Event
An intermediate event is a fault event that occurs because of one or more antecedent causes acting through logic gates. All intermediate events are symbolized by rectangles.
Event Symbols used in a Fault Tree Analysis
Gates
There are two basic types of fault tree gates: the OR-gate and the AND-gate. All other gates are really special cases of these two basic types.
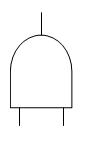
OR-gate
The OR-gate is used to show that the output event occurs only if one or more of the input events occur. There may be any number of input events to an OR-gate.
AND-gate
The AND-gate is used to show that the output fault occurs only if all the input faults occur. There may be any number of input faults to an AND-gate.
INHIBIT-gate
The INHIBIT-gate, represented by the hexagon, is a special case of the AND-gate. The output is caused by a single input, but some qualifying condition must be satisfied before the input can produce the output. The condition that must exist is the conditional input. A description of this conditional input is spelled out within an ellipse drawn to the right of the gate.
EXCLUSIVE OR-gate
The EXCLUSIVE OR-gate is a special case of the OR-gate in which the output event occurs only if exactly one of the input events occur
PRIORITY AND-gate
The PRIORITY AND-gate is a special case of the AND-gate in which the output event occurs only if all input events occur in a specified ordered sequence. The sequence is usually shown inside an ellipse drawn to the right of the gate. In practice, the necessity of having a specific sequence is not usually encountered.
Gate Symbols used in a Fault Tree Analysis
Procedure
Identify the system or process that will be examined, including boundaries that will limit the analysis. FTA often stems from a previous risk assessment, such as a FMEA or Structured What-If; or, it comes from a root cause analysis.
Identify the Top Event, the type of failure that will be analyzed as narrowly and specifically as possible.
Identify the events that may be immediate cause sof the top event. Write these events at the level below te event they cause.
For each event ask “Is this a basic failure? Or can it be analyzed for its immediate causes?”
If the event is a basic failure, draw a circle around it.
If it can be analyzed for its own causes draw a rectangle around it (NOTE: if appropriate, other event types are possible)
Ask “How are these events related to the one they cause?” Use the gate symbols to show the relationships. The lower-level events are the input events. They one they cause, above the gate is the output event.
For each event that is not basic, repeat steps 4 and 5. Continue until all branches of the tree end in a basic or undeveloped event.
To determine the mathematical probability of failure, assign probabilities to each of the basic events. Use Boolean algebra to calculate the probability of each high-level event and the top event. Discussions of the math is a very different post.
Analyze the tree to understand the relations between the causes and to find ways to prevent failures. Use the gate relationships to find the most efficient ways to reduce risk. Focus attention on the causes most likely to happen.
FTA example using lack of team (basic)
The Question Tree
A critical task in problem-solving is determining what kinds of analysis and corresponding data would best solve the problem. Rather than a shortage of techniques, there are too many to choose from, we can often reflexively use the same few, basic tools out of familiarity and habit. This can mislead when the situation is complex, non-routine, and/or unfamiliar.
This is where a Question Tree comes in handy to determine what analyses and data are suited for a particular problem-solving situation. This tool is also known as a logic tree or a decision tree. Question Trees are structures for seeing the elements of a problem clearly, and keeping track of different levels of the problem, which we can liken to trunks, branches, twigs, and leaves. You can arrange them from left to right, right to left, or top to bottom— whatever makes the elements easier for you to visualize. Think of a Question Tree as a mental model of your problem. Better trees have a clearer and more complete logic of relationships linking the parts to each other, are more comprehensive and have no overlap.
The Question Tree is very powerful when working through broad and complex problems that no single analysis or framework can solve. By developing a set of questions that are connected to one another in the form of a tree we can determine what data analysis is needed, which can help us break out of the habit of using the same analysis tool even when it is a bad one for the job.
The core question is the starting point. It is made easier to solve by decomposing it into a few, more specific sub-questions. The logic of decomposition is such that the answers to these sub-questions should together fully answer the question they emerge from. The first level of sub-questions may still be too broad to solve with specific analyses and data, so each is decomposed further.
The process of decomposition continues until a sub-question is reached that can be answered using a particular technique or framework, and the data needed is specific enough to be identified. A Question Tree is thus constructed, and the final set of questions indicates the analyses and data needed. As much as possible, the questions on the tree are also framed such that they have “yes” or “no” as potential answers.
They, too, are hypotheses to be settled with data, analysis, and evidence. They can also be used to test assumptions and beliefs, evaluate expectations, explore puzzles and oddities, and generate solution options.
In decomposing a question, ask whether the sub-questions are mutually exclusive and collectively exhaustive. This can help generate the sub-question not asked, and thus, reduce errors of omission. Building a Question Tree is an iterative and nonlinear process. If later information so dictates, previously done work on the tree should be adjusted.
Judgment plays a role in building a Question Tree, so it is unlikely that two people working independently on a complex starting question will create identical trees, but these are bound to overlap. Expertise matters and the strength of teams should be leveraged.
Success and Cause Trees
These are variations of the fault tree analysis: a Success Tree where the top event is desired and a Cause Tree used to investigate a past event as part of root cause analysis.
Risk assessment is a pillar of the quality system because it gives us the ability to anticipate in a consistent manner. It is built on some fundamental criteria:
When I teach an introductory risk management class, I usually use an icebreaker of “What is the riskiest activity you can think of doing. Inevitably you will get some version of skydiving, swimming with sharks, jumping off bridges. This activity is great because it starts all conversations around likelihood and severity. At heart, the question brings out the concept of risk important activities and the nature of controls.
The things people think of, such as skydiving, are great examples of activities that are surrounded by activities that control risk. The very activity is based on accepting reducing risk as low as possible and then proceeding in the safest possible pathway. These risk important activities are the mechanism just before a critical step that:
Ensure the appropriate transfer of information and skill
Ensure the appropriate number of actions to reduce risk
Influence the presence or effectiveness of barriers
Influence the ability to maintain positive control of the moderation of hazards
Risk important activities is a concept important to safety-thought and are at the center of a lot of human error reduction tools and practices. Risk important activities are all about thinking through the right set of controls, building them into the procedure, and successfully executing them before reaching the critical step of no return. Checklists are a great example of this mindset at work, but there are a ton of ways of doing them.
In the hospital they use a great thought process, “Five rights of Safe Medication Practices” that are: 1) right patient, 2) right drug, 3) right dose, 4) right route, and 5) right time. Next time you are getting medication in the doctor’s office or hospital evaluate just what your caregiver is doing and how it fits into that process. Those are examples of risk important activities.
Assessing controls during risk assessment
Risk is affected by the overall effectiveness of any controls that are in place.
The key aspects of controls are:
the mechanism by which the controls are intended to modify risk
whether the controls are in place, are capable of operating as intended, and are achieving the expected results
whether there are shortcomings in the design of controls or the way they are applied
whether there are gaps in controls
whether controls function independently, or if they need to function collectively to be effective
whether there are factors, conditions, vulnerabilities or circumstances that can reduce or eliminate control effectiveness including common cause failures
A risk can have more than one control and controls can affect more than one risk.
We always want to distinguish between controls that change likelihood, consequences or both, and controls that change how the burden of risk is shared between stakeholders
Any assumptions made during risk analysis about the actual effect and reliability of controls should be validated where possible, with a particular emphasis on individual or combinations of controls that are assumed to have a substantial modifying effect. This should take into account information gained through routine monitoring and review of controls.
Risk Important Activities, Critical Steps and Process
Critical steps are the way we meet our critical-to-quality requirements. The activities that ensure our product/service meets the needs of the organization.
These critical steps are the points of no-return, the point where the work-product is transformed into something else. Risk important activities are what we do to remove the danger of executing that critical step.
Beyond that critical step, you have rejection or rework. When I am cooking there is a lot of prep work which can be a mixture of critical steps, from which there is no return. I break the egg wrong and get eggshells in my batter, there is a degree of rework necessary. This is true for all our processes.
The risk-based approach to the process is to understand the critical steps and mitigate controls.
We are thinking through the following:
Critical Step: The action that triggers irreversibility. Think in terms of critical-to-quality attributes.
Output: The desired result (positive) or the possible difficulty (negative)
Preconditions: Technical conditions that must exist before the critical step
Resources: What is needed for the critical step to be completed
Local factors: Things that could influence the critical step. When human beings are involved, this is usually what can influence the performer’s thinking and actions before and during the critical step
Good risk management requires a mindset that includes the following attributes:
Expect to be surprised: Our processes are usually underspecified and there is a lot of hidden knowledge. Risk management serves to interrogate the unknowns
Possess a chronic sense of unease: There is no such thing as perfect processes, procedures, training, design, planning. Past performance is not a guarantee of future success.
Bend, not break: Everything is dynamic, especially risk. Quality comes from adaptability.
One cannot control risk, or even successfully identify it unless a system is able flexibly to monitor both its own performance (what happens inside the system’s boundary) and what happens in the environment (outside the system’s boundary). Monitoring improves the ability to cope with possible risks
When performing the risk assessment, challenge existing monitoring and ensure that the right indicators are in place. But remember, monitoring itself is a low-effectivity control.
Ensure that there are leading indicators, which can be used as valid precursors for changes and events that are about to happen.
For each monitoring control, as yourself the following:
How have the indicators been defined? (By analysis, by tradition, by industry consensus, by the regulator, by international standards, etc.)
Relevance
When was the list created? How often is it revised? On which basis is it revised? Who is responsible for maintaining the list?
Type
How many of the indicators are of the ‘leading,’ type and how many are of the lagging? Do indicators refer to single or aggregated measurements?
Validity
How is the validity of an indicator established (regardless of whether it is leading or lagging)? Do indicators refer to an articulated process model, or just to ‘common sense’?
Delay
For lagging indicators, how long is the typical lag? Is it acceptable?
Measurement type
What is the nature of the measurements? Qualitative or quantitative? (If quantitative, what kind of scaling is used?)
Measurement frequency
How often are the measurements made? (Continuously, regularly, every now and then?)
Analysis
What is the delay between measurement and analysis/interpretation? How many of the measurements are directly meaningful and how many require analysis of some kind? How are the results communicated and used?
Stability
Are the measured effects transient or permanent?
Organization Support
Is there a regular inspection scheme or -schedule? Is it properly resourced? Where does this measurement fit into the management review?