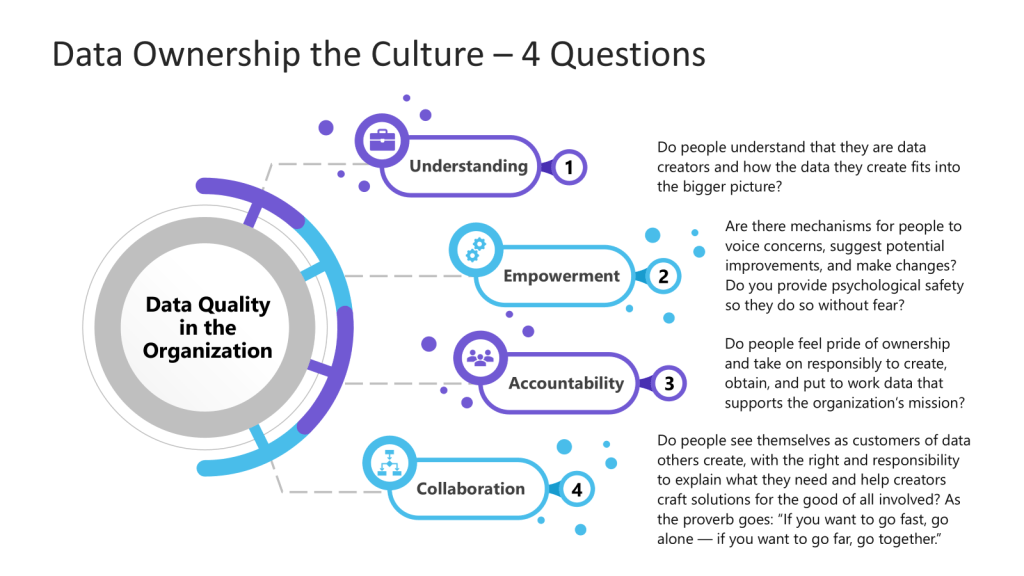
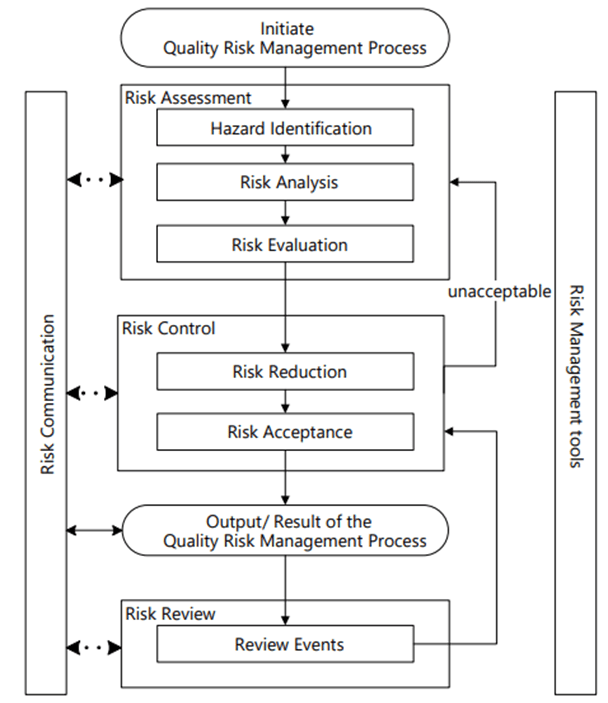
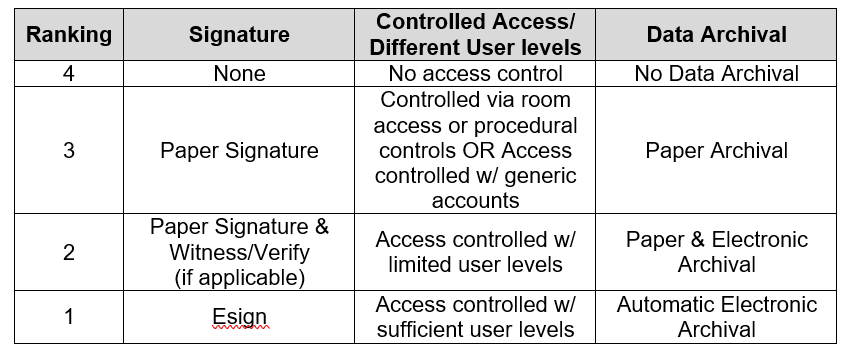
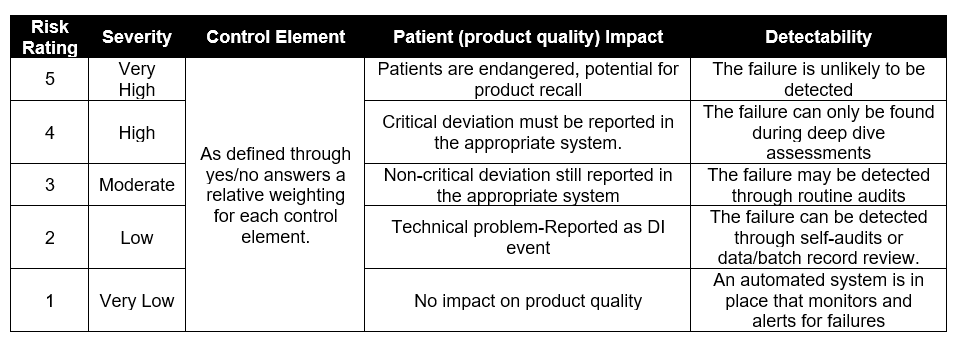
Data-driven decision-making is an essential component for achieving organizational success. Simply adopting the latest technologies or bringing on board data scientists is not enough to foster a genuinely data-driven culture. Instead, it requires a comprehensive strategy that involves every level of the organization.
This holistic approach emphasizes the importance of empowering all employees—regardless of their role or technical expertise—to effectively utilize data in their daily tasks and decision-making processes. It involves providing training and resources that enhance data literacy, enabling individuals to understand and interpret data insights meaningfully. Moreover, organizations should cultivate an environment that encourages curiosity and critical thinking around data. This might include promoting cross-departmental collaboration where teams can share insights and best practices regarding data use. Leadership plays a vital role in this transformation by modeling data-driven behaviors and championing a culture that values data as a critical asset. By prioritizing data accessibility and encouraging open dialogue about data analytics, organizations can truly empower their workforce to harness the potential of data, driving informed decisions that contribute to overall success and innovation.
The Three Pillars of Data Empowerment
To build a robust data-driven culture, leaders must focus on three key areas of readiness:
Data Readiness: The Foundation of Informed Decision-Making
Data readiness ensures that high-quality, relevant data is accessible to the right people at the right time. This involves:
- Implementing robust data governance policies
- Investing in data management platforms
- Ensuring data quality and consistency
- Providing secure and streamlined access to data
By establishing a strong foundation of data readiness, organizations can foster trust in their data and encourage its use across all levels of the company.
Analytical Readiness: Cultivating Data Literacy
Analytical readiness is a crucial component of building a data-driven culture. While access to data is essential, it’s only the first step in the journey. To truly harness the power of data, employees need to develop the skills and knowledge necessary to interpret and derive meaningful insights. Let’s delve deeper into the key aspects of analytical readiness:
Comprehensive Training on Data Analysis Tools
Organizations must invest in robust training programs that cover a wide range of data analysis tools and techniques. This training should be tailored to different skill levels and job functions, ensuring that everyone from entry-level employees to senior executives can effectively work with data.
- Basic data literacy: Start with foundational courses that cover data types, basic statistical concepts, and data visualization principles.
- Tool-specific training: Provide hands-on training for popular data analysis tools and the specialized business intelligence platforms that are adopted.
- Advanced analytics: Offer more advanced courses on machine learning, predictive modeling, and data mining for those who require deeper analytical skills.
Developing Critical Thinking Skills for Data Interpretation
Raw data alone doesn’t provide value; it’s the interpretation that matters. Employees need to develop critical thinking skills to effectively analyze and draw meaningful conclusions from data.
- Data context: Teach employees to consider the broader context in which data is collected and used, including potential biases and limitations.
- Statistical reasoning: Enhance understanding of statistical concepts to help employees distinguish between correlation and causation, and to recognize the significance of findings.
- Hypothesis testing: Encourage employees to formulate hypotheses and use data to test and refine their assumptions.
- Scenario analysis: Train staff to consider multiple interpretations of data and explore various scenarios before drawing conclusions.
Encouraging a Culture of Curiosity and Continuous Learning
A data-driven culture thrives on curiosity and a commitment to ongoing learning. Organizations should foster an environment that encourages employees to explore data and continuously expand their analytical skills.
- Data exploration time: Allocate dedicated time for employees to explore datasets relevant to their work, encouraging them to uncover new insights.
- Learning resources: Provide access to online courses, webinars, and industry conferences to keep employees updated on the latest data analysis trends and techniques.
- Internal knowledge sharing: Organize regular “lunch and learn” sessions or internal workshops where employees can share their data analysis experiences and insights.
- Data challenges: Host internal competitions or hackathons that challenge employees to solve real business problems using data.
Fostering Cross-Functional Collaboration to Share Data Insights
Data-driven insights become more powerful when shared across different departments and teams. Encouraging cross-functional collaboration can lead to more comprehensive and innovative solutions.
- Interdepartmental data projects: Initiate projects that require collaboration between different teams, combining diverse datasets and perspectives.
- Data visualization dashboards: Implement shared dashboards that allow teams to view and interact with data from various departments.
- Regular insight-sharing meetings: Schedule cross-functional meetings where teams can present their data findings and discuss potential implications for other areas of the business.
- Data ambassadors: Designate data champions within each department to facilitate the sharing of insights and best practices across the organization.
By investing in these aspects of analytical readiness, organizations empower their employees to make data-informed decisions confidently and effectively. This not only improves the quality of decision-making but also fosters a culture of innovation and continuous improvement. As employees become more proficient in working with data, they’re better equipped to identify opportunities, solve complex problems, and drive the organization forward in an increasingly data-centric business landscape.
Infrastructure Readiness: Enabling Seamless Data Operations
To support a data-driven culture, organizations must have the right technological infrastructure in place. This includes:
- Implementing scalable hardware solutions
- Adopting user-friendly software for data analysis and visualization
- Ensuring robust cybersecurity measures to protect sensitive data
- Providing adequate computing power for complex data processing
- Build a clear and implementable qualification methodology around data solutions
With the right infrastructure, employees can work with data efficiently and securely, regardless of their role or department.
The Path to a Data-Driven Culture
Building a data-driven culture is an ongoing process that requires commitment from leadership and active participation from all employees. Here are some key steps to consider:
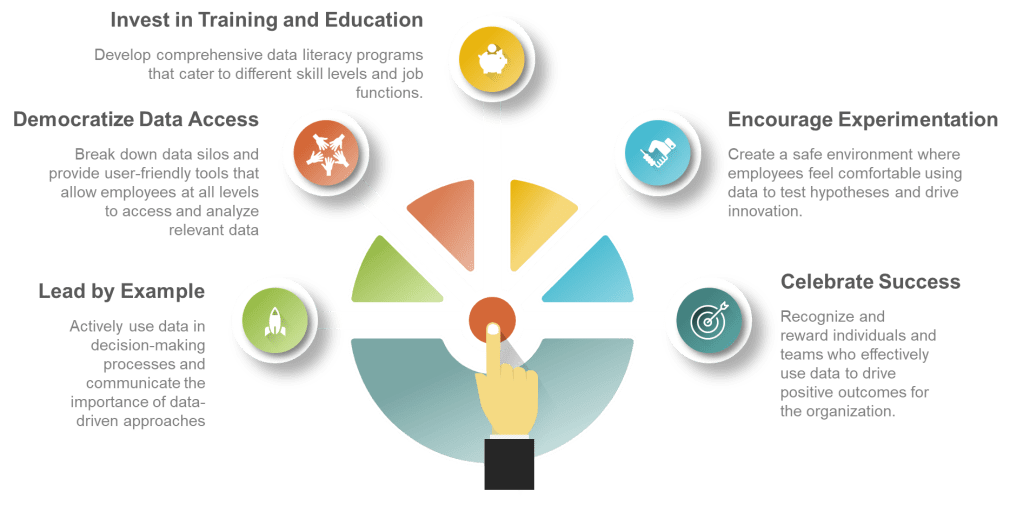
- Lead by example: Executives should actively use data in their decision-making processes and communicate the importance of data-driven approaches.
- Democratize data access: Break down data silos and provide user-friendly tools that allow employees at all levels to access and analyze relevant data.
- Invest in training and education: Develop comprehensive data literacy programs that cater to different skill levels and job functions.
- Encourage experimentation: Create a safe environment where employees feel comfortable using data to test hypotheses and drive innovation.
- Celebrate data-driven successes: Recognize and reward individuals and teams who effectively use data to drive positive outcomes for the organization.
Conclusion
To build a truly data-driven culture, leaders must take everyone along on the journey. By focusing on data readiness, analytical readiness, and infrastructure readiness, organizations can empower their employees to harness the full potential of data. This holistic approach not only improves decision-making but also fosters innovation, drives efficiency, and ultimately leads to better business outcomes.
Remember, building a data-driven culture is not a one-time effort but a continuous process of improvement and adaptation. By consistently investing in these three areas of readiness, organizations can create a sustainable competitive advantage in today’s data-centric business landscape.