In the current world scenario, which is marked by high volatility, uncertainty, complexity, and ambiguity (VUCA), threats are increasingly unforeseen. As organizations, we are striving for this concept of Resilience.
Resilience is one of those hot words, and like many hot business terms it can mean a few different things depending on who is using it, and that can lead to confusion. I tend to see the following uses, which are similar in theme.
Where used
Meaning
Physics
The property of a material to absorb energy when deformed and not fracture nor break; in other words, the material’s elasticity.
Ecology
The capacity of an ecosystem to absorb and respond to disturbances without permanent damage to the relationships between species.
Psychology
An individual’s coping mechanisms and strategies.
Organizational and Management studies
The ability to maintain an acceptable level of service in the face of periodic or catastrophic systemic and singular faults and disruptions (e.g. natural disasters, cyber or terrorist attacks, supply chain disturbances).
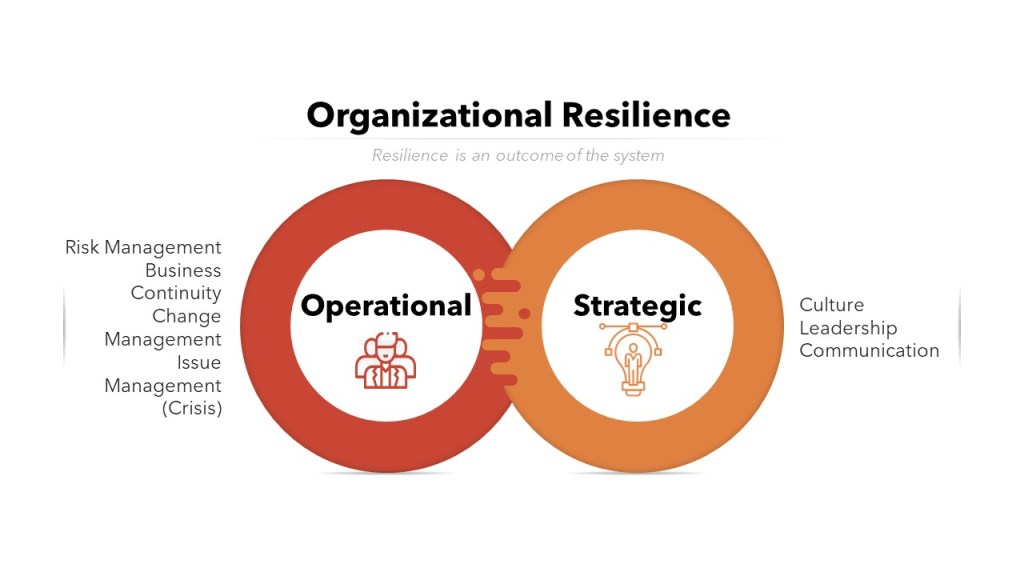
For our purposes, resilience can be viewed as the ability of an organization to maintain quality over time, in the face of faults and disruptions. Given we live in a time of disruption, resilience is obviously of great interest to us.
In my post “Principles behind a good system” I lay out eight principles for good system development. Resilience is not a principle, it is an outcome. It is through applying our principles we gain resilience. However, like any outcome we need to design for it deliberately.
I recently had a discussion with one of the best root cause investigators and problem solvers I know, Thor McRockhammer. Thor had concerns about a case where the expected conditions were not met and there were indications that individuals engaged in troubleshooting and as a result not only made the problem worse but led to a set of issues that seem rather systematic.
Our conversation (which I do not want to go into too much detail on) was a great example of troubleshooting going wrong.
Troubleshooting is defined as “Reactive problem solving based upon quick responses to immediate symptoms. Provides relief and immediate problem mitigation. But may fail to get at the real cause, which can lead to prolonged cycles of firefighting.” Troubleshooting usually goes wrong one of a few ways:
Not knowing when troubleshooting shouldn’t be executed
Using troubleshooting exclusively
Not knowing when to go to other problem solving tools (usually “Gap from standard”) or to trigger other quality systems, such as change management.
Troubleshooting is a reactive process of fixing problems by rapid response and short-term corrective actions. It covers noticing the problem, stopping the damage and preventing spread of the problem.
So if our departure from expected conditions was a leaky gasket, then troubleshooting is to try to stop the leak. If our departure is a missing cart then troubleshooting usually involves finding the cart.
Troubleshooting puts things back into the expected condition without changing anything. It addresses the symptom and not the fundamental problems and their underlying causes. They are carried out directly by the people who experience the symptoms, relying upon thorough training, expertise and procedures designed explicitly for troubleshooting.
With out leaky gasket example, our operators are trained and have procedural guidance to tighten or even replace a gasket. They also know what not to do (for example don’t weld the pipe, don’t use a different gasket, etc). There is also a process for documenting the troubleshooting happened (work order, comment, etc).
To avoid the problems listed above troubleshooting needs a process that people can be thoroughly trained in. This process needs to cover what to do, how to communicate it, and where the boundaries are.
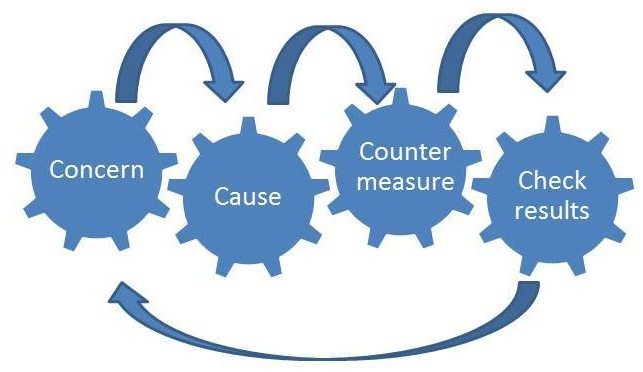
·What do we known about the exact nature of the problem?
·What do your
standards say about how this concern should be documented?
oFor example,
can be addressed as a comment or does it require a deviation or similar non-conformance
·If the concern stems
from a requirement it must be documented.
Cause
·What do you
know about the apparent (or root) cause of the problem?
·Troubleshooting
is really good at dealing with superficial cause-and-effect relationships. As
the cause deepens, fixing it requires deeper problem-solving.
·The cause can
be a deficiency or departure from a standard
Countermeasure
·What immediate
or temporary countermeasures can be taken to reduce or eliminate the problem?
·Are follow-up
or more permanent countermeasures required to prevent recurrence?
oIf so, do you
need to investigate more deeply?
·Countermeasures
need to be evaluated against change management
·Countermeasures
cannot ignore, replace or go around standards
·Apply good
knowledge management
Check results
·Did the results
of the action have any immediate effect on eliminating the concern or
problem?
·Does the
problem repeat?
oIf so, do you
need to investigate more deeply?
·Recurrence
should trigger deeper problem-solving and be recorded in the quality system.
·Beware troubleshooting
countermeasures becoming tribal knowledge and the new way of working
Trouble shooting is in a box
Think of your standards as a box. This box defines what should happen per our qualified/validated state, our procedures, and the like. We can troubleshoot as much as we want within the box. We cannot change the box in any way, nor can we leave the box without triggering our deviation/nonconformance system (reactive) or entering change management (proactive).
Communication is critical for troubleshooting
Troubleshooting processes need a mechanism for letting supervisors happen. Troubleshooting that happens in the dark is going to cause a disaster.
Operators need to be trained how to document troubleshooting. Sometimes this is as simple as a notation or comment, other-times you trigger a corrective action process.
Engaging in troubleshooting, and not documenting it starts to look a like fraud and is a data integrity concern.
Change Management
The change management process should be triggered as a result of troubleshooting. Operators should be trained to interpret it. This is often were concept of exact replacements and like-for-like come in.
It is trouble shooting to replace a part with an exact part. Anything else (including functional equivalency) is a higher order change management activity. It is important that everyone involved knows the difference.
Covers
Is it troubleshooting?
Like-for- Like
Spare parts that are identical replacements (has the same the same manufacturer, part number, material of construction, version)
Existing contingency procedures (documented, verified, ideally part of qualification/validation)
Yes
This should be built into procedures like corrective maintenance, spare parts, operations and even contingency procedures.
Functionally equivalent
Equivalent, for example, performance, specifications, physical characteristics, usability, maintainability, cleanability, safety
No
Need to understand root cause. Need to undergo appropriate level of change management
New
Anything else
No
Need to understand root cause. Need to undergo appropriate level of change management
This applies to both administrative and technical controls.
ITIL Incident Management
ITIL Incident Management (or similar models) is just troubleshooting and has all the same hallmarks and concerns.
Conclusion
Trouble shooting is an integral process. And like all processes it should have a standard, be trained on, and go through continuous improvement.