Stephanie Gaulding, a colleague in the ASQ, recently wrote an excellent post for Redica on “How to Avoid Three Common Deviation Investigation Pitfalls“, a subject near and dear to my heart.
The three pitfalls Stephanie gives are:
- Not getting to root case
- Inadequate scoping
- Treating investigations the same
All three are right on the nose, and I’ve posted a bunch on the topics. Definitely go and read the post.
What I want to delve deeper into is Stephanie’s point that “Deviation systems should also be built to triage events into risk-based categories with sufficient time allocated to each category to drive risk-based investigations and focus the most time and effort on the highest risk and most complex events.”
That is an accurate breakdown, and exactly what regulators are asking for. However, I think the implementation of risk-based categories can sometimes lead to confusion, and we can spend some time unpacking the concept.
Risk is the possible effect of uncertainty. Risk is often described in terms of risk sources, potential events, their consequences, and their likelihoods (where we get likelihoodXseverity from).
But there are a lot of types of uncertainty, IEC31010 “Risk management – risk management techniques” lists the following examples:
- uncertainty as to the truth of assumptions, including presumptions about how people or systems might behave
- variability in the parameters on which a decision is to be based
- uncertainty in the validity or accuracy of models which have been established to make predictions about the future
- events (including changes in circumstances or conditions) whose occurrence, character or consequences are uncertain
- uncertainty associated with disruptive events
- the uncertain outcomes of systemic issues, such as shortages of competent staff, that can have wide ranging impacts which cannot be clearly defined lack of knowledge which arises when uncertainty is recognized but not fully understood
- unpredictability
- uncertainty arising from the limitations of the human mind, for example in understanding complex data, predicting situations with long-term consequences or making bias-free judgments.
Most of these are only, at best, obliquely relevant to risk categorizing deviations.
So it is important to first build the risk categories on consequences. At the end of the day these are the consequence that matter in the pharmaceutical/medical device world:
- harm to the safety, rights, or well-being of patients, subjects or participants (human or non-human)
- compromised data integrity so that confidence in the results, outcome, or decision dependent on the data is impacted
These are some pretty hefty areas and really hard for the average user to get their minds around. This is why building good requirements, and understanding how systems work is so critical. Building breadcrumbs in our procedures to let folks know what deviations are in what category is a good best practice.
There is nothing wrong with recognizing that different areas have different decision trees. Harm to safety in GMP can mean different things than safety in a GLP study.
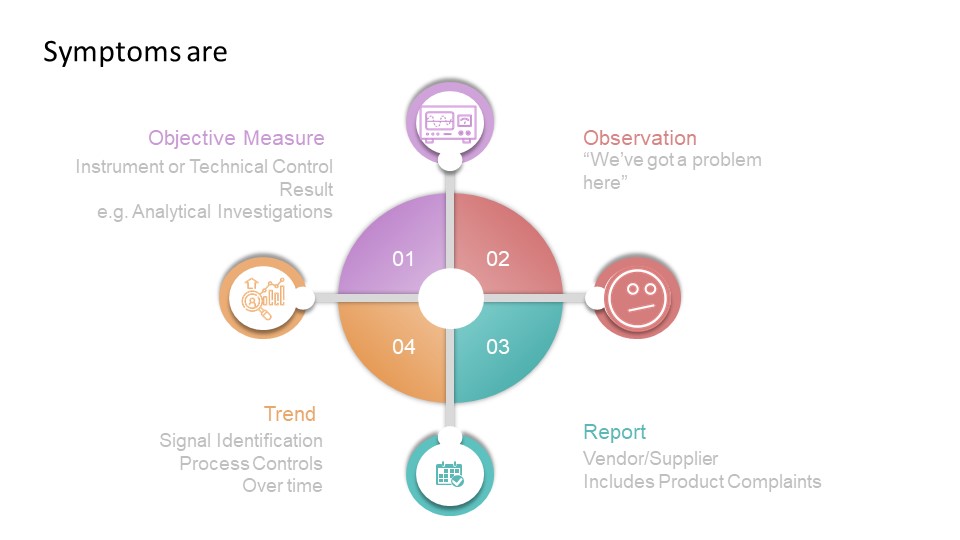
The second place I’ve seen this go wrong has to do with likelihood, and folks getting symptom confused with problem confused with cause.

All deviations are with a situation that is different in some way from expected results. Deviations start with the symptom, and through analysis end up with a root cause. So when building your decision-tree, ensure it looks at symptoms and how the symptom is observed. That is surprisingly hard to do, which is why a lot of deviation criticality scales tend to focus only on severity.

13 thoughts on “Treating All Investigations the Same”