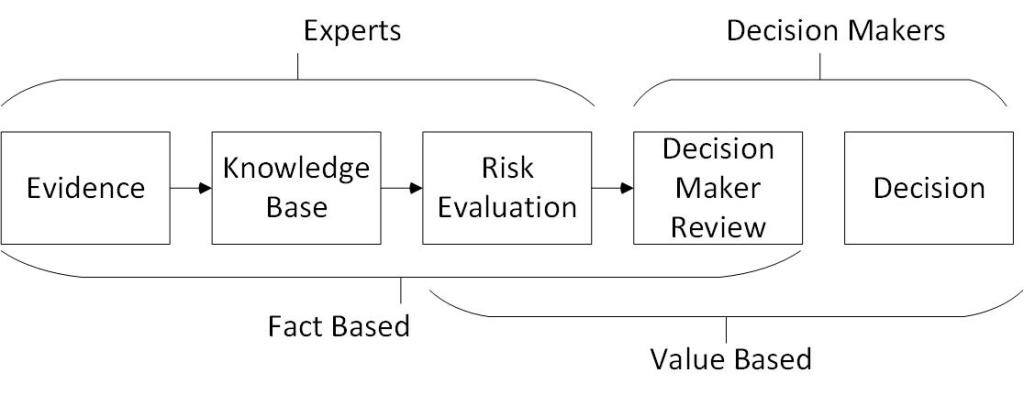
These experiments show some preliminary evidence that the color assignment in risk matrices might influence people’s perception of risk gravity, and therefore their decisionmaking with regards to risk mitigation. We found that individuals might be tempted to cross color boundaries when reducing risks even if this option is not advantageous (i.e., the boundary crossing effect). However, this effect was not consistently found when we included exploratory analyses of
Proto, R., Recchia, G., Dryhurst, S., & Freeman, A. L. J. (2023). Do colored cells in risk matrices affect decision-making and risk perception? Insights from randomized controlled studies. Risk Analysis, 43, 2114–2128. https://doi.org/10.1111/risa.14091
risk mitigations at different impact levels.
Pending future research replicating these results, the cautious recommendation is that the potential biasing effects of color should be considered alongside the goal of communication. If the purpose of communication is informing individuals in an unbiased way, these findings suggest it might be worth eliminating colors from risk matrices in order to reduce the risk of the boundary-crossing effect. On the other hand, if the goal of communication is to persuade individuals to implement certain risk mitigation actions, it might be that assigning colors so as to elicit the boundary-crossing effect would facilitate this. This could be the case, for example, when designing risk matrices that communicate action standards (i.e., severity level at which risk mitigation should be implemented) (Keller et al., 2009). This advice might be particularly relevant in the case of semiqualitative risk matrices, where color assignment might be arbitrary due to the absence of clear numeric cut-off points separating risk severity categories, and to situations where the users of the risk matrix are expected to be of higher numeracy and not have prior training in the design and use of risk matrices.
Well, that is thought-provoking. I guess I need to start evaluating the removal of a lot of color from SOPs, work instructions, and templates.